

19
Nov
เจาะลึกเหตุการณ์ Cloudflare ล่มทั่วโลก 18 พ.ย. เผย ต้องตัดทราฟฟิกเพื่อกู้ระบบ
in Blog
Comments
Cloudflare ล่มทั่วโลก 18 พฤศจิกายน 2025: เมื่อโครงข่ายหลักของอินเทอร์เน็ตสะดุดพร้อมกัน
เช้าวันที่ 18 พฤศจิกายน 2025 ตามเวลา UTC โครงข่ายของ Cloudflare ผู้ให้บริการ CDN และโครงสร้างพื้นฐานอินเทอร์เน็ตรายใหญ่ของโลกเริ่มเกิดปัญหา ส่งผลให้ผู้ใช้งานจำนวนมหาศาลทั่วโลกเข้าเว็บไซต์และบริการออนไลน์ไม่ได้ และพบหน้า Error 5xx จาก Cloudflare แทน สิ่งที่เกิดขึ้นไม่ใช่การโจมตีไซเบอร์ หรือ DDoS ระลอกใหม่อย่างที่หลายคนคาด แต่กลับมาจาก “การเปลี่ยนแปลงสิทธิ์การเข้าถึงฐานข้อมูลภายใน” ที่ดูเหมือนเล็กน้อย ทว่ากลายเป็นจุดเริ่มต้นของความล้มเหลวแบบลูกโซ่ในระบบ Proxy ระดับแกนกลางของบริษัท Cloudflare ระบุชัดในรายงานว่า เหตุการณ์ครั้งนี้เป็นหนึ่งในเหตุขัดข้องที่เลวร้ายที่สุดนับตั้งแต่ปี 2019 และยอมรับว่า ช่วงเวลาที่ทราฟฟิกหลักของลูกค้าไม่สามารถผ่านเครือข่ายได้เลย ถือเป็น “บาดแผลใหญ่” สำหรับทีมวิศวกรรมทุกคน ท่ามกลางแรงกดดันนั้น สิ่งที่ทีมต้องตัดสินใจทำอย่างเร่งด่วนคือการ “ตัดและเปลี่ยนเส้นทางทราฟฟิกบางส่วน” เพื่อกู้ระบบให้กลับมาทำงานได้ไวที่สุด แม้ต้องยอมลดฟีเจอร์หรือกดบริการบางอย่างลงชั่วคราวก็ตาม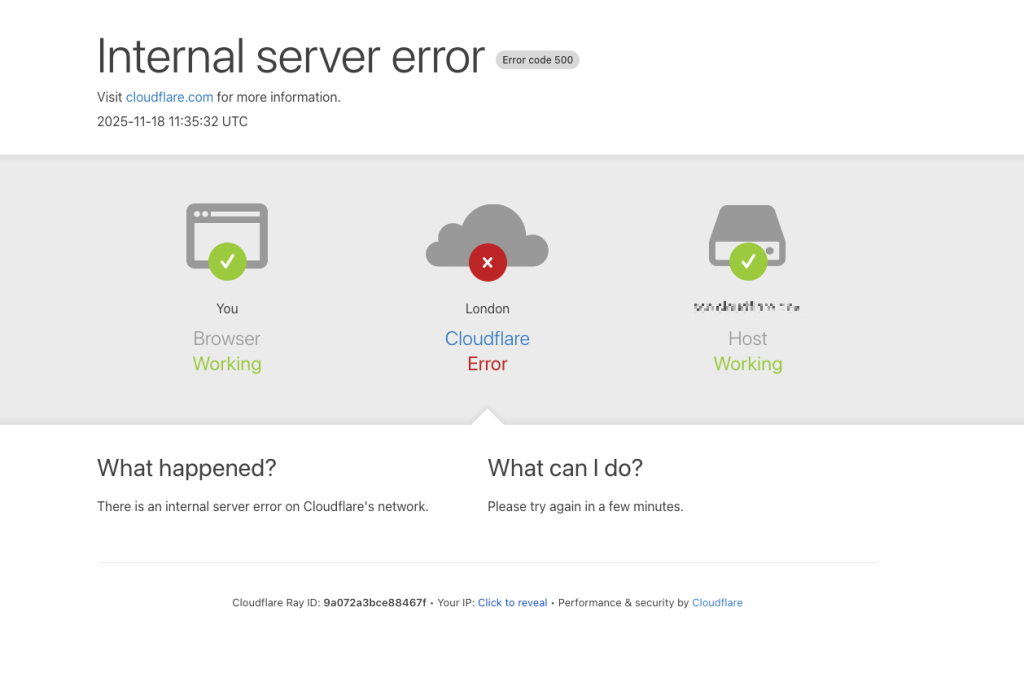
ต้นตอปัญหา: ไฟล์ Feature ของ Bot Management โตเกินจนทำ Proxy ล่ม
หัวใจของเหตุการณ์เริ่มต้นจากงานด้าน Security เอง นั่นคือระบบ Bot Management ของ Cloudflare ที่ใช้ Machine Learning วิเคราะห์ทราฟฟิกว่าเป็นบอทหรือมนุษย์ ข้อมูลที่โมเดลใช้จะถูกเก็บในรูปแบบ “feature file” ซึ่งสร้างใหม่ทุกไม่กี่นาทีจากฐานข้อมูล ClickHouse เพื่อให้เครือข่ายทั่วโลกอัปเดตสัญญาณภัยคุกคามล่าสุดอยู่เสมอ Cloudflareได้ปรับการจัดการสิทธิ์ในฐานข้อมูล โดยทำให้ผู้ใช้สามารถเห็น Metadata ของตารางใน Schema ระดับล่างได้มากขึ้น แต่ Query ที่ใช้สร้าง feature file เดิมออกแบบมาภายใต้สมมติฐานว่า ผลลัพธ์จะมีเฉพาะข้อมูลจาก Database หลัก เมื่อสิทธิ์ใหม่ทำให้ Query ดึงข้อมูลจากหลาย Schema ได้พร้อมกัน จึงเกิด “ค่า Duplicate” จำนวนมากในผลลัพธ์ และทำให้จำนวน Feature ที่บันทึกลงไฟล์เพิ่มขึ้นมากกว่าสองเท่าในคราวเดียว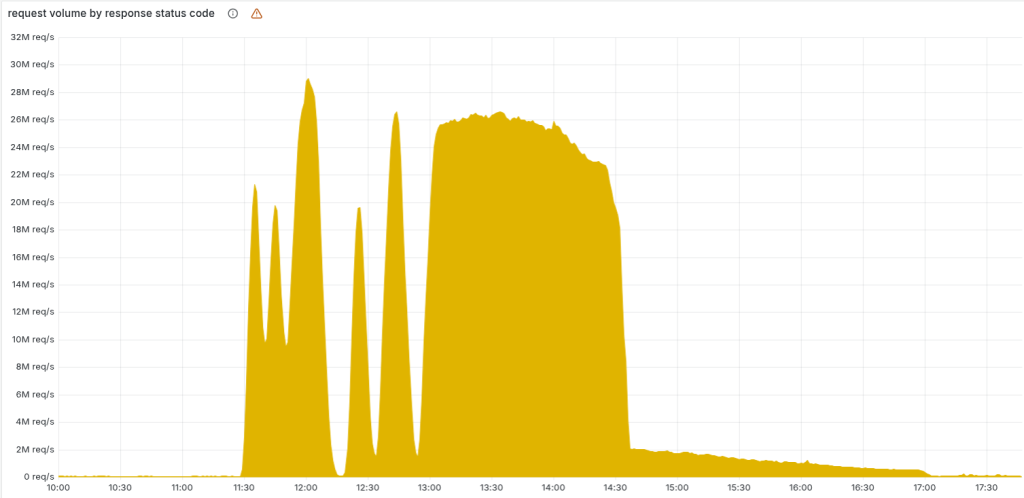
ซอฟต์แวร์ Proxy รุ่นใหม่ของ Cloudflare (FL2) ถูกออกแบบให้ Pre-allocate หน่วยความจำสำหรับ Feature ตามจำนวนสูงสุดที่กำหนดไว้ (ประมาณ 200 Feature) เพื่อไม่ให้กินทรัพยากรเกินคาด เมื่อไฟล์ Feature ที่เสียหายถูกเผยแพร่ไปยังเซิร์ฟเวอร์ทั่วโลกและมีจำนวน Feature เกินเพดาน ระบบจึงเข้าสู่สถานะ “panic” และโยน Error จนเกิด HTTP 5xx ในระดับเครือข่ายหลัก ยิ่งไปกว่านั้น ไฟล์ Feature ถูกสร้างทุก ๆ ห้านาทีบนคลัสเตอร์ ClickHouse ที่อยู่ระหว่างการอัปเดต ทำให้บางรอบได้ไฟล์ “ดี” บางรอบได้ไฟล์ “เสีย” ผลที่เห็นคือระบบฟื้นขึ้นมาเองช่วงสั้น ๆ แล้วก็ตกลงไปในสถานะล้มเหลวอีกครั้งเป็นระยะ ๆ ลักษณะกราฟ Error ที่ขึ้นลงแบบนี้ ทำให้ทีมปฏิบัติการเข้าใจในตอนแรกว่าอาจเป็น DDoS ขนาดใหญ่ ก่อนจะค่อย ๆ ไล่ย้อนและพบว่าจริง ๆ แล้วปัญหามาจากการตั้งค่าภายในตัวเอง
บริการอะไรได้รับผลกระทบบ้างเมื่อ Cloudflare สะดุด
เมื่อ Proxy ระดับแกนกลางเริ่มตอบสนองผิดพลาด ผลกระทบจึงกระจายไปเกือบทุกบริการที่ผูกอยู่กับโครงสร้างพื้นฐานเดียวกัน เริ่มจาก Core CDN และบริการด้านความปลอดภัยที่ตอบกลับด้วย HTTP 5xx ผู้ใช้ทั่วไปจึงเห็นหน้า Error ของ Cloudflare ในเว็บไซต์และแอปพลิเคชันมากมายทั่วโลก พร้อมกันในช่วงเวลาไม่กี่ชั่วโมง บริการ Turnstile ซึ่งใช้ตรวจสอบและยืนยันตัวตนผู้ใช้ก่อนเข้าสู่ระบบ ก็ได้รับผลกระทบ จนทำให้ลูกค้าหลายรายไม่สามารถล็อกอินเข้า Dashboard ของ Cloudflare ได้ หากไม่ได้มี Session เดิมค้างอยู่ ขณะเดียวกัน Workers KV ซึ่งเป็น Data Store สำคัญของแพลตฟอร์ม Worker ก็เริ่มตอบ Error เพิ่มขึ้นอย่างมีนัยสำคัญ เพราะพึ่งพา Proxy ตัวเดียวกัน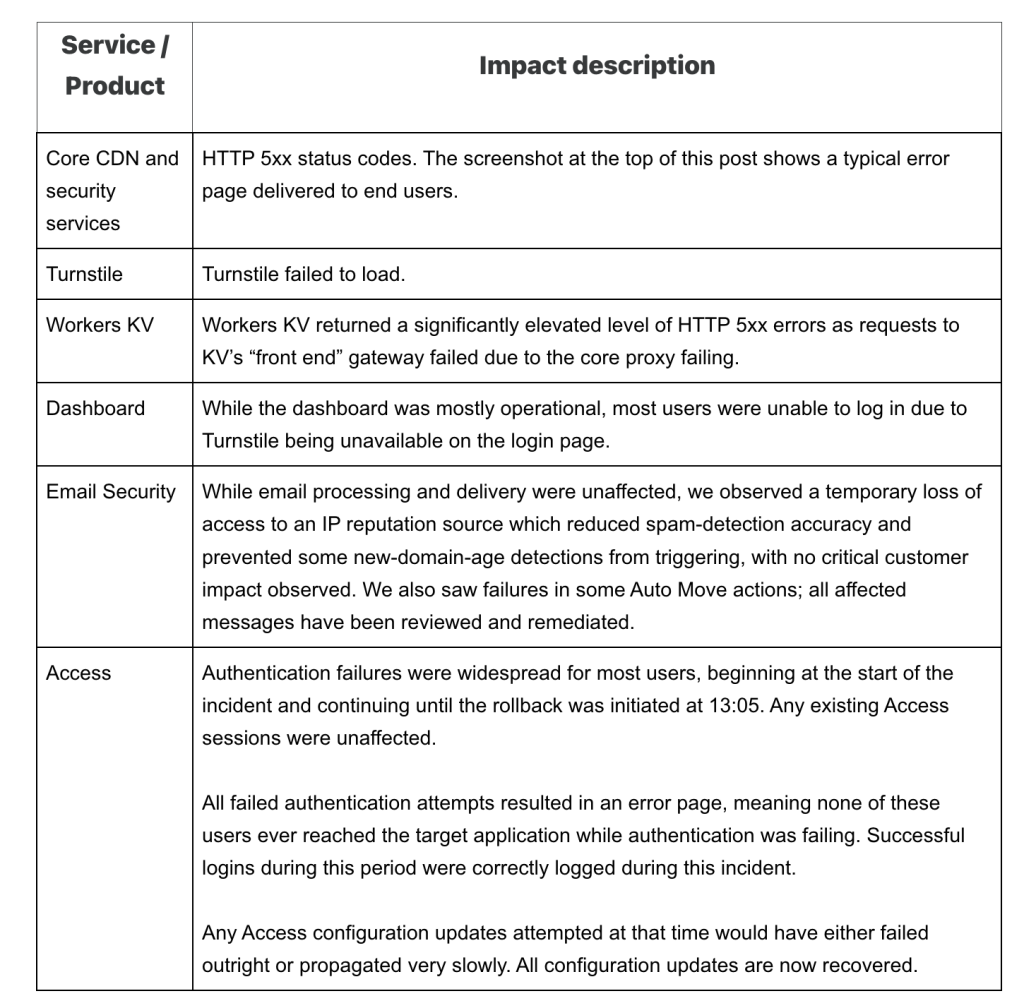
แม้บริการ Email Security ยังส่งและรับอีเมลได้ตามปกติ แต่ Cloudflare พบว่าการเข้าถึงข้อมูลด้าน Reputation บางส่วนสะดุด ทำให้ความแม่นยำในการตรวจสแปมลดลงชั่วคราว ในขณะที่ Cloudflare Access ซึ่งใช้ควบคุมการเข้าถึงแอปพลิเคชันภายในองค์กร ก็เกิดปัญหาการยืนยันตัวตนเป็นวงกว้าง ผู้ใช้จำนวนหนึ่งจึงเข้าไม่ถึงระบบที่ใช้ Cloudflare เป็นชั้นควบคุมหน้าประตู เมื่อภาพรวมทั้งหมดถูกนำมาประกอบกัน เหตุการณ์ครั้งนี้จึงไม่ใช่แค่ “เว็บไซต์บางแห่งล่ม” แต่เป็นการสะดุดของโครงข่ายที่อยู่กลางระหว่างผู้ใช้กับบริการดิจิทัลนับไม่ถ้วน ตั้งแต่เว็บเล็ก ๆ ไปจนถึงแพลตฟอร์มขนาดใหญ่ระดับโลก
แผนกู้ระบบ: ตัดทราฟฟิกบางส่วน Bypass Proxy และย้อนกลับไฟล์ที่ดี
จุดเปลี่ยนสำคัญของเหตุการณ์อยู่ในช่วงเวลาที่ทีมวิศวกรรมเริ่มยอมรับว่า ปัญหาอาจไม่ได้อยู่ที่ปริมาณทราฟฟิกภายนอก แต่เกิดจากการทำงานของ Proxy และบริการภายในเอง ก่อนจะมุ่งไปที่ Bot Management และไฟล์ Feature ที่ถูกสร้างจาก ClickHouse การตัดสินใจในช่วงไม่กี่สิบนาทีหลังจากนั้น ทำให้บริการหลายอย่างกลับมาหายใจได้อีกครั้ง แม้จะยังไม่สมบูรณ์ทั้งหมดก็ตาม ในช่วงแรกของการรับมือ ทีมงานพยายามเยียวยาระดับบริการเฉพาะ เช่น Workers KV ด้วยการ “จัดการทราฟฟิก” และจำกัดบัญชีบางส่วน เพื่อลดโหลดและหวังให้บริการกลับสู่ระดับปกติ เมื่อเห็นว่ายังไม่เพียงพอ จึงตัดสินใจใช้เส้นทาง Bypass ภายในให้ Workers KV และ Cloudflare Access ข้าม Proxy รุ่นใหม่ กลับไปใช้ Proxy รุ่นก่อนหน้าแทน แม้ปัญหาเรื่อง Bot Score จะยังอยู่ แต่ระดับผลกระทบต่อทราฟฟิกหลักลดลงอย่างชัดเจน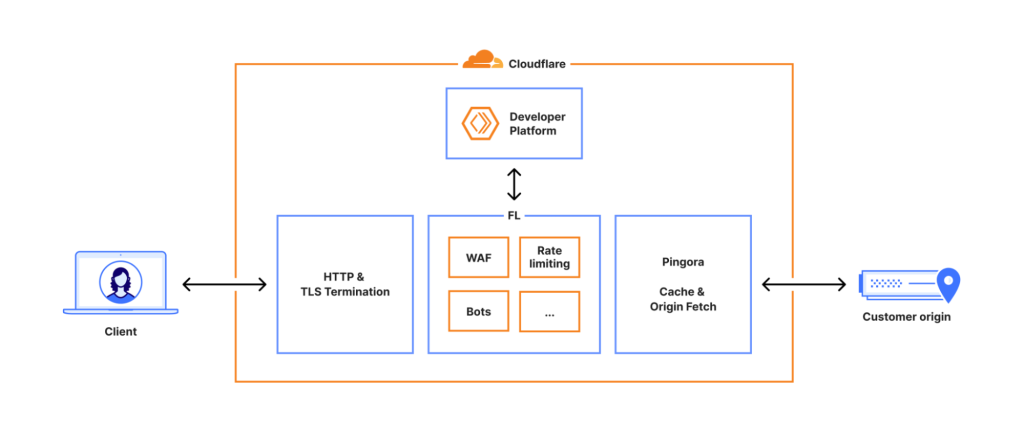 หลังจากนั้น ทีมงานจึงหันไปโฟกัสกับการกู้คืนจากต้นเหตุ คือ Bot Management configuration file ที่ใช้ในเครือข่ายทั่วโลก มีการหยุดสร้างและหยุดกระจายไฟล์รุ่นใหม่ แล้วแทนที่ด้วยไฟล์เวอร์ชันที่ทราบแน่ชัดว่า “ดีและปลอดภัย” ก่อนจะบังคับให้ Proxy รีสตาร์ตเพื่อโหลดค่าคอนฟิกชุดเดิมกลับมา เมื่อขั้นตอนนี้เสร็จสิ้นในช่วงประมาณ 14:30 UTC ทราฟฟิกหลักของลูกค้าส่วนใหญ่ก็เริ่มกลับมาทำงานได้ใกล้เคียงปกติ
แม้ภาพรวมจะถือว่ากู้ระบบกลับมาได้ภายในไม่กี่ชั่วโมง แต่คิวการร้องขอและการล็อกอินที่ค้างสะสมจำนวนมากยังคงสร้างภาระให้กับ Dashboard และ API ภายในอีกระยะหนึ่ง ทีมงานจึงต้องเพิ่มขีดความสามารถในการประมวลผลของ Control Plane เพื่อระบายโหลด และจัดการรีสตาร์ตบริการต่าง ๆ ที่อยู่ในสถานะไม่ปกติให้ครบ จนกระทั่งเวลา 17:06 UTC จึงประกาศว่าระบบทั้งหมดกลับมาทำงานได้ตามปกติ
หลังจากนั้น ทีมงานจึงหันไปโฟกัสกับการกู้คืนจากต้นเหตุ คือ Bot Management configuration file ที่ใช้ในเครือข่ายทั่วโลก มีการหยุดสร้างและหยุดกระจายไฟล์รุ่นใหม่ แล้วแทนที่ด้วยไฟล์เวอร์ชันที่ทราบแน่ชัดว่า “ดีและปลอดภัย” ก่อนจะบังคับให้ Proxy รีสตาร์ตเพื่อโหลดค่าคอนฟิกชุดเดิมกลับมา เมื่อขั้นตอนนี้เสร็จสิ้นในช่วงประมาณ 14:30 UTC ทราฟฟิกหลักของลูกค้าส่วนใหญ่ก็เริ่มกลับมาทำงานได้ใกล้เคียงปกติ
แม้ภาพรวมจะถือว่ากู้ระบบกลับมาได้ภายในไม่กี่ชั่วโมง แต่คิวการร้องขอและการล็อกอินที่ค้างสะสมจำนวนมากยังคงสร้างภาระให้กับ Dashboard และ API ภายในอีกระยะหนึ่ง ทีมงานจึงต้องเพิ่มขีดความสามารถในการประมวลผลของ Control Plane เพื่อระบายโหลด และจัดการรีสตาร์ตบริการต่าง ๆ ที่อยู่ในสถานะไม่ปกติให้ครบ จนกระทั่งเวลา 17:06 UTC จึงประกาศว่าระบบทั้งหมดกลับมาทำงานได้ตามปกติ
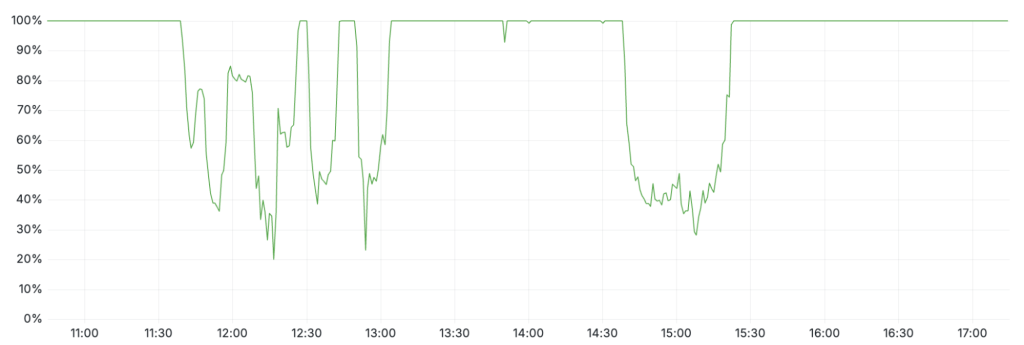
เหตุการณ์นี้ชี้ให้เห็นภาพชัดเจนว่า การกู้ระบบในระดับโครงข่ายโลก ไม่ได้หมายถึงการ “เปิดทุกอย่างกลับมาในครั้งเดียว” แต่ต้องเริ่มจากการตัดทราฟฟิกบางส่วน อ้อมเลี่ยงชั้นบริการที่มีปัญหา และค่อย ๆ นำส่วนประกอบต่าง ๆ กลับมาอย่างระมัดระวัง เพื่อไม่ให้การฟื้นตัวเองกลายเป็นต้นเหตุของเหตุขัดข้องระลอกใหม่
บทเรียนสำหรับองค์กรไทย: อย่ามองข้ามการป้องกัน “ความผิดพลาดจากภายใน”
แม้เหตุการณ์ครั้งนี้จะเกิดขึ้นกับผู้ให้บริการระดับ Global อย่าง Cloudflare แต่บทเรียนที่สะท้อนออกมาเกี่ยวข้องโดยตรงกับองค์กรไทยแทบทุกประเภท โดยเฉพาะทีมที่ดูแลระบบขนาดใหญ่หรือพึ่งพาบริการ Cloud/CDN เป็นส่วนหนึ่งของโครงสร้างพื้นฐาน การเปลี่ยนแปลงเล็ก ๆ เช่นการปรับสิทธิ์ฐานข้อมูล หรือการเขียน Query โดยสมมติฐานที่ไม่ครบถ้วน สามารถส่งผลสะท้อนเป็นปัญหาระดับระบบทั้งหมดได้ หากไม่มี Guardrail ที่ดีพอ Cloudflare ระบุชัดว่าขั้นตอนต่อไปคือการทำให้ระบบรับไฟล์คอนฟิกที่สร้างจากภายในถูกตรวจสอบเข้มงวดไม่ต่างจาก Input ที่มาจากผู้ใช้ภายนอก เพิ่มกลไก Kill Switch ระดับ Global สำหรับฟีเจอร์หลัก และออกแบบให้ระบบ Error Reporting หรือการสร้าง Core Dump ไม่สามารถกลายเป็นภาระเพิ่มให้กับทรัพยากรจนทำให้ระบบล้มเองได้ พร้อมกันนั้นยังเป็นโอกาสทบทวน Failure Mode ของโมดูลสำคัญทั้งหมดใน Proxy ว่าเมื่อพลาดแล้วควร “ล้มแบบปลอดภัย” อย่างไร
Cloudflare ระบุชัดว่าขั้นตอนต่อไปคือการทำให้ระบบรับไฟล์คอนฟิกที่สร้างจากภายในถูกตรวจสอบเข้มงวดไม่ต่างจาก Input ที่มาจากผู้ใช้ภายนอก เพิ่มกลไก Kill Switch ระดับ Global สำหรับฟีเจอร์หลัก และออกแบบให้ระบบ Error Reporting หรือการสร้าง Core Dump ไม่สามารถกลายเป็นภาระเพิ่มให้กับทรัพยากรจนทำให้ระบบล้มเองได้ พร้อมกันนั้นยังเป็นโอกาสทบทวน Failure Mode ของโมดูลสำคัญทั้งหมดใน Proxy ว่าเมื่อพลาดแล้วควร “ล้มแบบปลอดภัย” อย่างไร
สำหรับองค์กรที่พึ่งพา Cloudflare หรือผู้ให้บริการโครงข่ายรายอื่น เหตุการณ์นี้คือสัญญาณเตือนว่าควรมีแผนสำรองด้านสถาปัตยกรรมและกระบวนการ เช่น การออกแบบเส้นทางทราฟฟิกสำรอง การเตรียม Playbook เมื่อผู้ให้บริการหลักล่ม การวางแผนสื่อสารภายในและกับลูกค้าเมื่อเกิดเหตุ รวมถึงการทบทวนว่าตนเองมี Single Point of Failure อยู่ตรงไหนบ้างในสายโซ่ระหว่างผู้ใช้กับบริการของเรา ท้ายที่สุด เหตุการณ์ 18 พฤศจิกายน 2025 ของ Cloudflare ทำให้เห็นชัดว่า “อินเทอร์เน็ตทั้งระบบ” พึ่งพาโครงสร้างพื้นฐานไม่กี่รายมากเพียงใด และย้ำเตือนทีมไอทีทุกคนว่า การออกแบบระบบให้ทนทานต่อความผิดพลาดจากภายใน ไม่ได้สำคัญน้อยไปกว่าการป้องกันการโจมตีจากภายนอกเลยแม้แต่น้อย
Reference
Prince, M. (2025, November 18). Cloudflare outage on November 18, 2025. The Cloudflare Blog. https://blog.cloudflare.com/18-november-2025-outage/หากสนใจสินค้า หรือต้องการคำปรึกษาเพิ่มเติม
💬 Line: @monsteronline
☎️ Tel: 02-026-6664
📩 Email: [email protected]
🌐 ดูสินค้าเพิ่มเติม: mon.co.th