

Azure Cosmos DB for PostgreSQL เป็นบริการฐานข้อมูลเชิงสัมพันธ์ที่มีการจัดการเต็มรูปแบบ สำหรับ PostgreSQL ขับเคลื่อนโดย open source ส่วนขยายของ Citrus ด้วยการ Remote ค้นข้อมูลจากระยะไกล รวมถึงการรองรับ JSON-B, geospatial data, rich indexing, และ high-performance scale-out, Cosmos DB สำหรับ PostgreSQL ช่วยให้ผู้ใช้สามารถสร้างแอปพลิเคชันแบบ on single หรือ multi-node clusters.
การแสดงภาพ Metrics และ Logs ที่สำคัญด้วยแดชบอร์ดที่ใช้งานได้ทันทีของ Datadog และใช้ automated monitors เพื่อติดตามความสมบูรณ์และประสิทธิภาพของฐานข้อมูล Azure Cosmos DB สำหรับ PostgreSQL
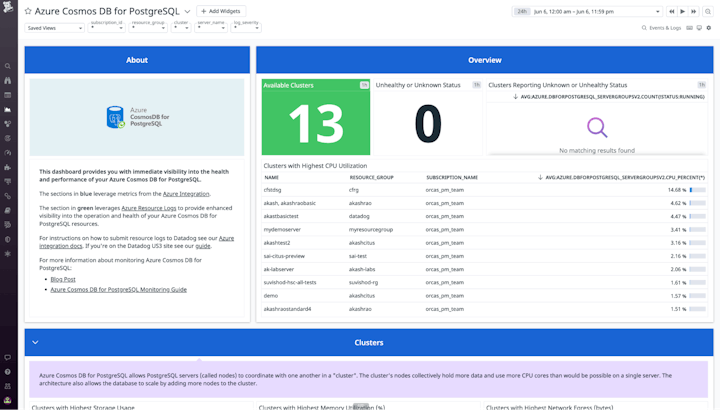
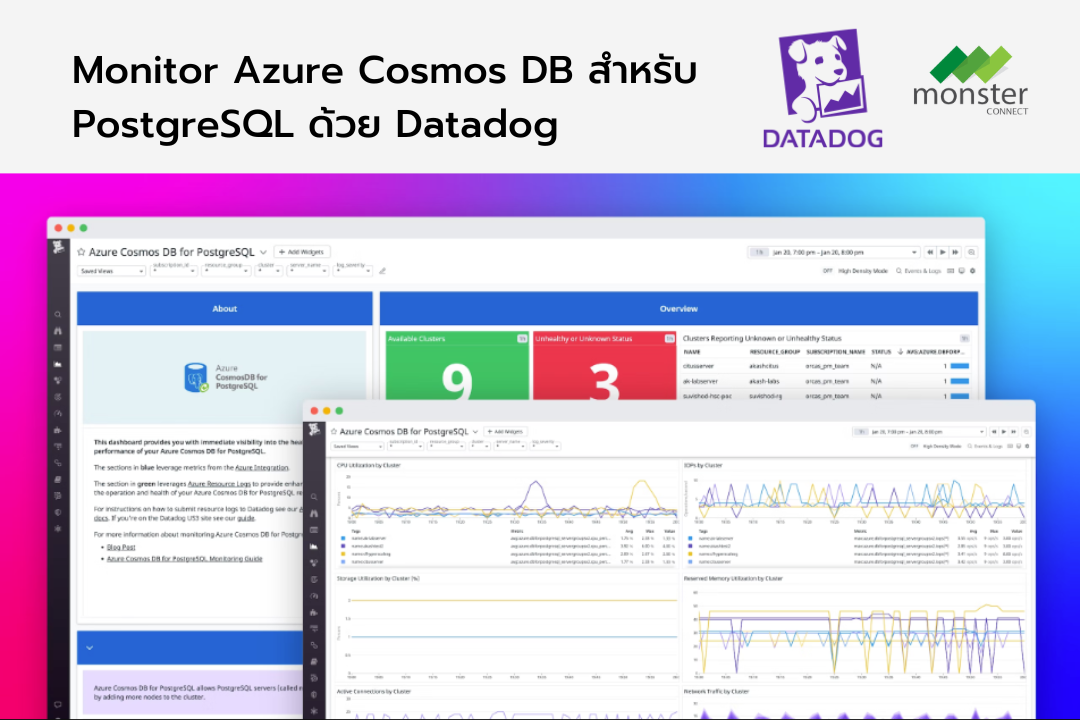
ตรวจสอบความสมบูรณ์ของ clusters
เมื่อตั้งค่า Azure Cosmos DB สำหรับ PostgreSQL environment เราสามารถจัดเตรียม clusters เพื่อ distribute load ได้ โดยทั่วไป clusters จะประกอบด้วย coordinator node และ one of more worker nodes
แอปพลิเคชันส่ง requests ไปยัง coordinator node ซึ่งจะกำหนด worker nodes ที่จะ query based ตามข้อมูลที่จำเป็นต้องเข้าถึง
ปรับขนาดของ Node และ cluster แบบเชิงรุก
Azure CosmosDB สำหรับ PostgreSQL ใช้ประโยชน์จาก distributed tables เพื่อ parallelize queries และ หลีกเลี่ยงการ overloading ของ node ใด node หนึ่ง แต่อย่างไรก็ตาม เมื่อฐานข้อมูลมีขนาดที่ใหญ่ขึ้นหรือความต้องการเพิ่มขึ้น อาจต้องมีการปรับเปลี่ยนขนาดของ cluster ในแนวนอน (โดยการเพิ่มเติม node) หรือในแนวตั้ง (โดยการเพิ่มขนาดของ node) แดชบอร์ดสำเร็จรูปของ Datadog สามารถระบุและปรับขนาดของ cluster ที่ต้องการ resources เพิ่มเติม
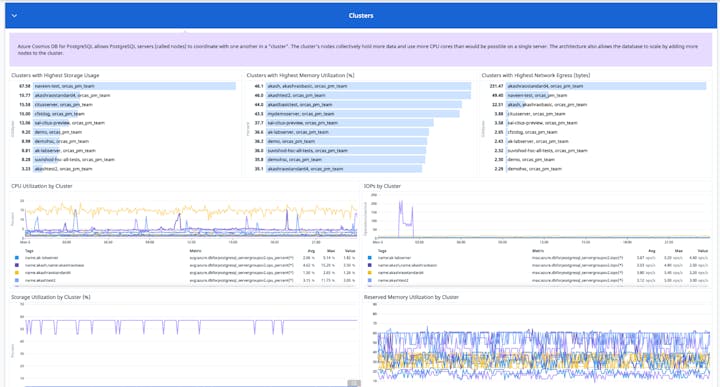
Azure Cosmos DB สำหรับ PostgreSQL มีตัวเลือกมากมาย สำหรับการกำหนดค่าจำนวน resources ที่พร้อมใช้งานสำหรับ available to the coordinator และ worker nodes in clusters
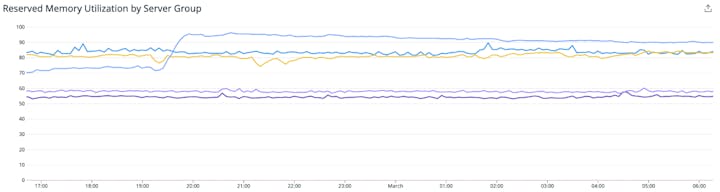
Reserved memory utilization (การใช้หน่วยความจำสำรอง) : PostgreSQL ใช้หน่วยความจำ เพื่อทำการ run ค้นหา Database อย่างรวดเร็ว มีประสิทธิภาพโดยไม่มีการเข้าถึงดิสก์ ถ้า database node มีหน่วยความจำไม่เพียงพอที่จะ run query จะทำให้เกิดข้อผิดพลาดต่อหน่วยจำที่ไม่เพียงพอ การตรวจสอบ metric การใช้หน่วยความจำที่สงวนไว้ สามารถช่วยระบุได้ว่า เมื่อแอปพลิเคชันใช้หน่วยความจำที่มีอยู่ของ clusters ในเปอร์เซ็นต์ที่สูง ซึ่งบ่งชี้ว่า cluster under ด้านหน่วยความจำ หากตัวชี้วัดเกิน 90 เปอร์เซ็นต์ใน clusters อย่างสม่ำเสมอ อาจจะต้องพิจารณาเพิ่ม node เพิ่มเติมเพื่อ distribute query load
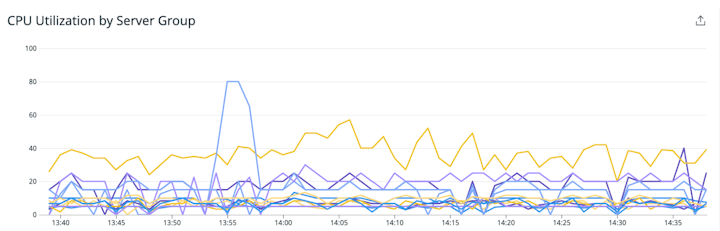
CPU utilization (การใช้งานซีพียู) : CPU เป็นหนึ่ง resource ที่จำเป็นสำหรับการรักษาให้ node ทำงานได้อย่างมีประสิทธิภาพ การใช้งาน CPU ที่เพิ่มขึ้นชั่วคราวอาจเกิดจากการ intensive query ดังนั้นจึงไม่จำเป็นต้องขยายขนาดของ cluster แต่ถ้าการใช้งาน CPU เกิน 95 เปอร์เซ็นต์ใน cluster เป็นประจำ บ่งชี้ได้เลยว่า node มีการ overloaded โดยอาจต้องพิจารณาขยายขนาดของ node
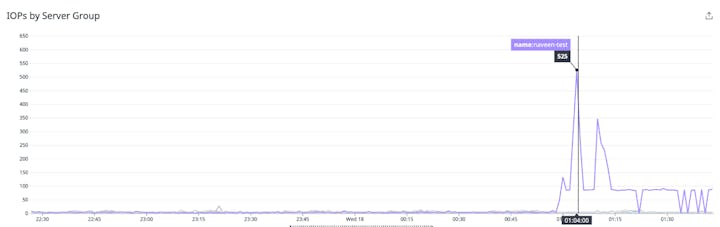
IOPS (ไอโพพีเอส) : การตรวจสอบ IOPS ของ node สามารถช่วยวัดกำหนดค่าความจุเพียงพอสำหรับการใช้งานหรือไม่ IOPS capacity ทั้งหมดที่มีใน cluster ขึ้นอยู่กับปริมาณของพื้นที่จัดเก็บที่จัดเตรียมไว้ เช่นเดียวกับจำนวน node ในกลุ่ม ตัวอย่างเช่น cluster ที่มีสอง node ของผู้ปฏิบัติงานแะล 2 TiB ของการจัดเก็บที่จัดเตรียมไว้จะมี IOPS capacity ทั้งหมด 12,296 หากเห็น IOPS ทั้งหมดใกล้ถึงความจุสูงสุดของ cluster ต้องมีการพิจารณาเพิ่ม node ของผู้ปฏิบัติงาน
Storage usage (การใช้พื้นที่เก็บข้อมูล) : นอกจากการจัดเก็บข้อมูลจาก database แล้ว node ยังต้องการพื้นที่จัดเก็บที่เพียงพอเพื่อรองรับการบันทึกและเก็บไฟล์ชั่วคราวสำหรับดำเนินการค้นหา หากการใช้พื้นที่เก็บข้อมูลเกิน 85 เปอร์เซ็นต์ ควรจะมีการขยายขนาดพื้นที่จัดเก็บ โดยการเพิ่มพื้นที่จัดเก็บข้อมูลให้กับ node ใน cluster หรืออาจพิจารณาขยายกลุ่มโดยเพิ่ม node ผู้ปฏิบัติงานเพิ่มเติม
ตัวชี้วัดและคำแนะนำทั้งหมดเหล่านี้ รวมอยู่ในแดชบอร์ดที่ใช้งานได้ทันที เพื่อให้ลูกทีมสามารถตรวจพบและแก้ไขปัญหาที่เจอได้ทันที
แจ้งเตือนปัญหา resource
สามารถตั้งค่าจอ monitors เพื่อรับการแจ้งเตือนปัญหาที่กำลังจะเกิดขึ้นได้โดยอัตโนมัติ ดังตัวอย่างในภาพด้านล่าง ที่สามารถกำหนดค่าการตรวจสอบการคาดการณ์ เพื่อตรวจจับว่าการใช้พื้นที่เก็บข้อมูลที่คาดว่าจะถึง 85 เปอร์เซ็นต์หรือไม่ ให้เวลาที่เพียงพอในการดำเนินการแก้ไขปัญหาโดยการลบ logs ที่ไม่ได้ใช้หรือขยายขนาดพื้นที่เก็บข้อมูลที่มีอยู่ใน node
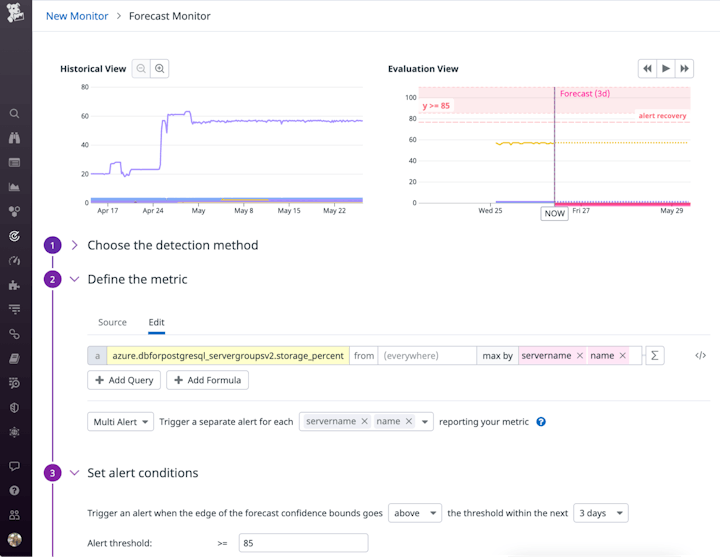
Anomaly monitors การตรวจสอบความผิดปกติ ยังมีประโยชน์ในการตรวจหาความผิดปกติในการใช้ resource ของ clusters ตัวอย่างเช่น การใช้งาน CPU โดยทั่วไปจะแตกต่างกันไปตามลักษณะของปริมาณงาน (เช่น การใช้งานที่สูงขึ้นในช่วงเวลาทำการ) ซึ่งอาจทำให้การ configure ตามเกณฑ์ที่กำหนดทำได้ยาก
การตรวจสอบความผิดปกตินี้ สามารถลดสัญญาณรบกวนโดยแยก factoring ในรูปแบบวันในสัปดาห์ และช่วงเวลาของวัน ได้โดยอัตโนมัติ เพื่อให้มั่นใจว่าจะได้รับการแจ้งเตือนเกี่ยวกับปัญหาจริงเท่านั้น (เช่น การใช้งาน CPU ที่เพิ่มขึ้นอย่างต่อเนื่องและสูงอย่างผิดปกติมากกว่าความผันผวนที่คาดไว้)
ตรวจสอบบันทึกเพื่อรับข้อมูลเชิงลึก
นอกจาก metics ที่กล่าวมาแล้ว การผสานรวมกับ Azure แบบฝังของ Datadog ยังช่วยให้สามารถรวบรวมบันทึกจาก Azure Cosmos DB สำหรับ PostgreSQL ได้ด้วยการคลิกเพียงไม่กี่ครั้ง
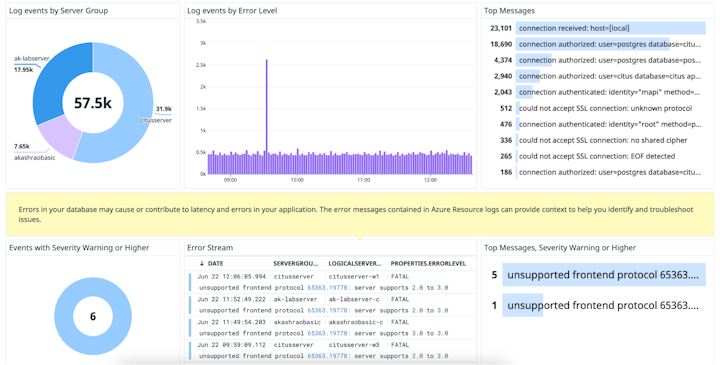
Resource logs อาจมีประโยชน์สำหรับการแก้ไขปัญหาการ configuration และปัญหาด้าน Performance ตัวอย่างเช่น Cosmos DB สำหรับ PostgreSQL กำหนดให้แอปพลิเคชันเชื่อมต่อโดยใช้ Transport Layer Security (TLS) หากแอปพลิเคชันไม่ได้เปิดใช้งานการเชื่อมต่อ TLS จะเห็นคำว่า could not accept SSL connection error logs
แดชบอร์ดสำเร็จรูปของ Datadog จะแสดง Azure Cosmos DB สำหรับ resource logs PostgreSQL จึงจะสามารถเชื่อมโยงกับเมตริกเพื่อตรวจสอบปัญหาด้าน performance และการกำหนดค่าผิดพลาดได้อย่างง่ายดาย สามารถใช้การแสดงภาพเหล่านี้เพื่อแสดงประเภท logs ที่ใช้บ่อยที่สุด, error logs ที่เพิ่งปล่อยออกมา และแนวโน้มอื่น ๆ
โดย Emily Chang
Akash Rao (Product Manager, Microsoft)
October 13, 2022
ข้อมูลเนื้อหาจาก datadoghq.com
สอบถามเพิ่มเติม
💬Line: @monsterconnect https://lin.ee/cCTeKBE
☎️Tel: 02-026-6664
📩Email: [email protected]
📝 Price List สินค้า https://bit.ly/3mSpuQY
🛍 Lazada Shop https://www.lazada.co.th/shop/monsteronline/
🛒 Shopee Online https://shopee.co.th/shop/849304465/
🏷 LINE SHOPPING https://shop.line.me/@monsterconnect
📺 YouTube : https://www.youtube.com/c/MonsterConnectOfficial
📲 TikTok : https://www.tiktok.com/@monsteronlines